【译文】使用 PodDisruptionBudgets 避免 Kubernetes 集群中断

使用 Kubernetes 中的中断预算来阻塞 Pod 驱逐
这是实现 Kubernetes 集群零停机时间更新旅程的第 4 部分。在前两篇文章(第二部分和第三部分)中,我们重点介绍了如何优雅关闭集群中存在的 Pod。我们介绍了如何使用 preStop 钩子优雅关闭 Pod,以及为何在序列中增加延迟以等待删除事件在集群中传播很重要。这可以处理一个 Pod 的终止,但不能阻止我们关闭太多 Pod 导致我们的服务无法正常运行。在本文中,我们将使用 PodDisruptionBudgets(或者简称为 PDB)来减轻这种风险。
PodDisruptionBudgets:预算可容忍的故障数
Pod 中断预算是一类 Pod 在给定时间可以容忍的中断数量的指标(故障预算)。每当计算出服务中的 Pod 中断导致 Service 降至预算以下时,操作就会暂停,直到可以维持预算为止。这意味着在等待更多 Pod 可用之前,可以暂时停止 drain 事件,以免驱逐 Pod 而超出预算。
要配置一个 Pod 中断预算,我们需要创建一个与 Service 中的 Pod 相匹配的 PodDisruptionBudgets 资源。例如,如果我们想要创建一个 Pod 中断预算,而我们总是希望至少有一个 Nginx Pod 可用于我们的示例 Deployment,我们将应用以下配置:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: nginx
这向 Kubernetes 表示我们希望至少有一个与标签 app: nginx 匹配的 Pod 在任何给定时间可用。使用此方法,我们可以促使 Kubernetes 在替换第 2 个 drain 请求中的 Pod 之前先等待第一个 drain 请求中的 Pod 被替换。
示例
为了说明它是如何工作的,让我们回到我们的示例。为了简单起见,在此示例中,我们将忽略所有的 preStop 钩子、就绪探针和服务请求。我们还将假设我们要对集群节点进行一对一替换。这意味着我们将通过使节点数量加倍来扩展集群,并使新节点运行新镜像。
因此,我们从两个节点的初始集群开始:
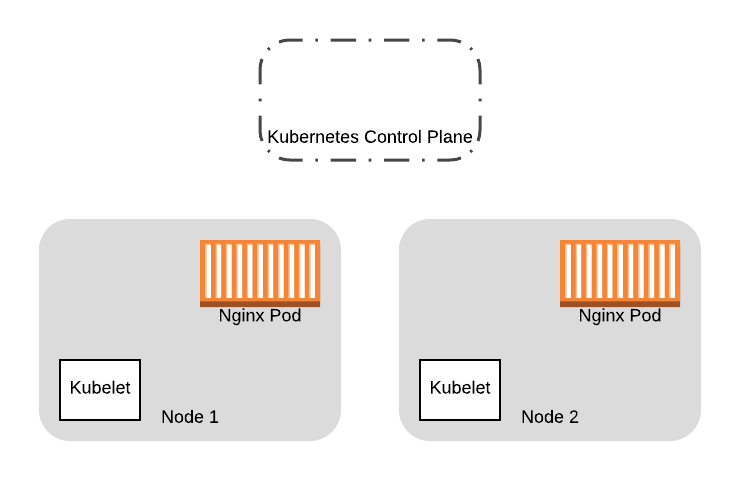
我们在此处提供了两个额外的节点,用于运行新的 VM 镜像。我们最终将旧节点上的所有 Pod 替换为新节点:
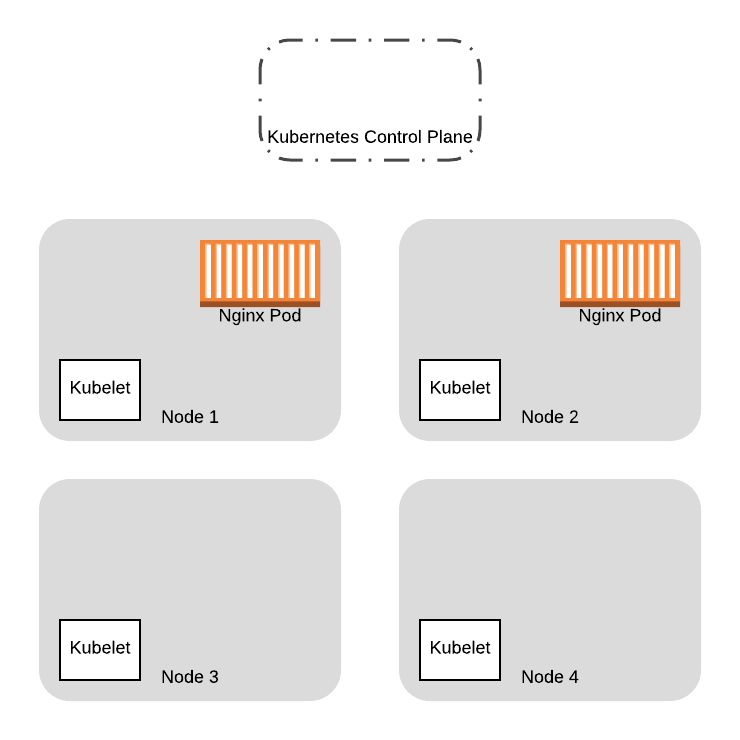
要替换 Pod,我们首先需要清空旧节点。在此示例中,让我们看看同时向 Nginx Pod 的两个节点发出 drain 命令时会发生什么。Drain 请求将在两个线程中发出(实际上,这只是两个终端选项卡),每个线程管理一个节点的 drain 序列。
请注意,到目前为止,我们通过假设 drain 命令立即发出驱逐请求来简化示例。实际上,drain 操作首先涉及对节点进行污染(具有 NoSchedule 污染标签),以便不会在节点上调度新的 Pod。对于此示例,我们将分别查看两个阶段。
因此,开始时,管理 drain 序列的两个线程将污染节点,从而不会调度新的 Pod:
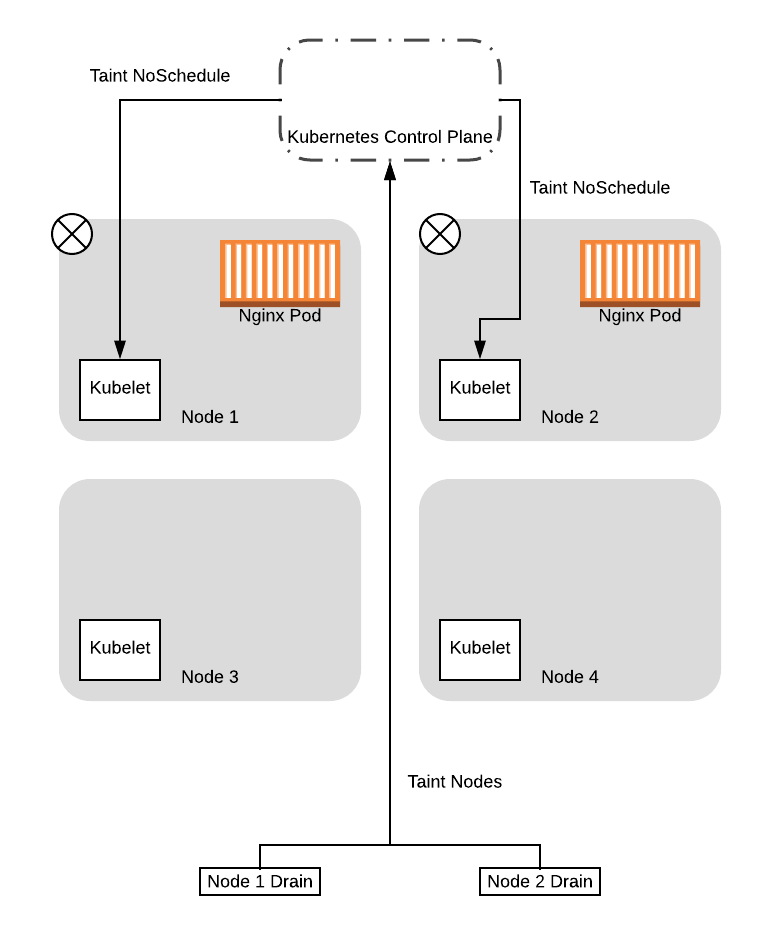
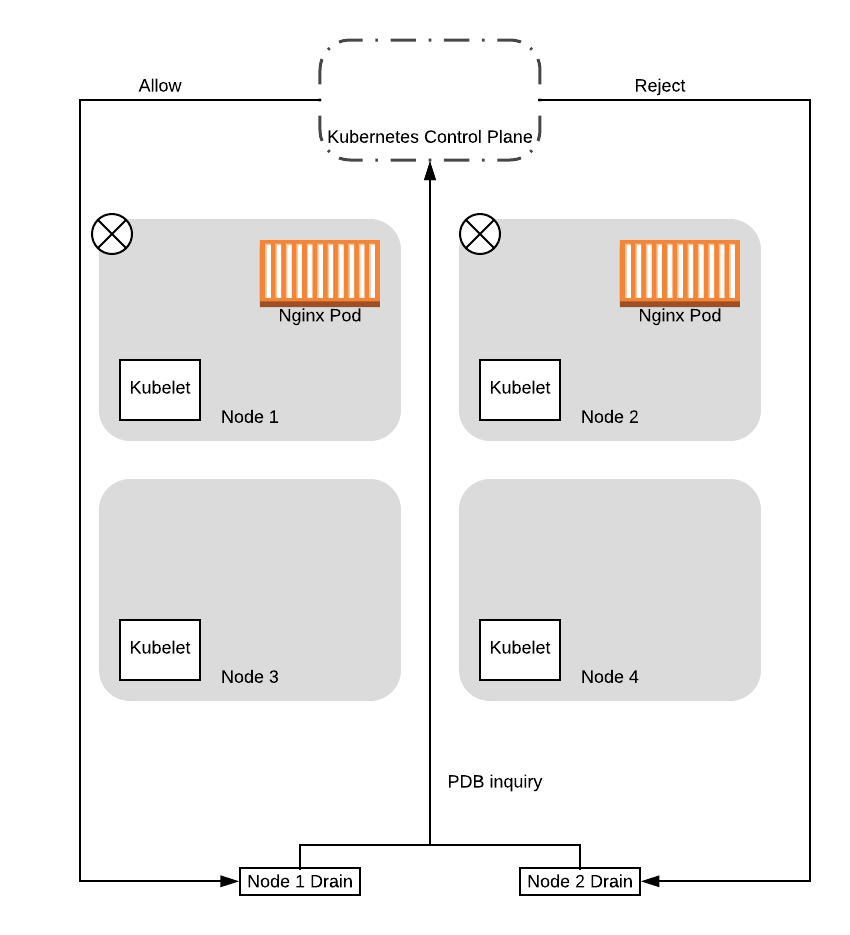
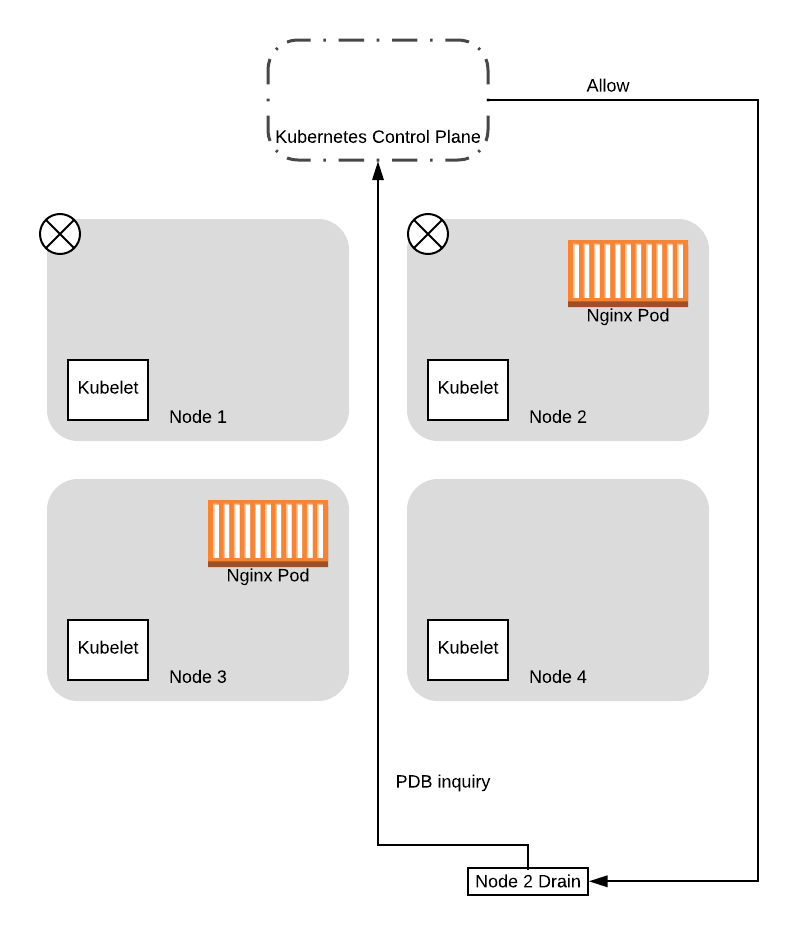
污染完成后,drain 线程将开始逐出节点上的 Pod。作为此操作的一部分,drain 线程将查询控制平面,以查看驱逐是否会导致 Service 下降到配置的 Pod 中断预算(PDB)以下。
请注意,控制平面将序列化请求,一次处理一个 PDB 查询。这样,在这种情况下,控制平面将成功响应其中一个请求,而使另一个请求失败。这是因为第一个请求基于两个可用的 Pod。允许此请求会将可用的 Pod 数量减少到 1,这意味着预算得以维持。当它允许请求继续进行时,然后将其中一个 Pod 逐出,从而变得不可用。到那时,当处理第二个请求时,控制平面将拒绝它,因为允许该请求会将可用容器的数量降至 0,低于我们配置的预算。
鉴于此,在此示例中,我们将假定节点 1 是获得成功响应的节点。在这种情况下,节点 1 的 drain 线程将继续驱逐 Pod,而节点 2 的 drain 线程将等待并稍后重试:
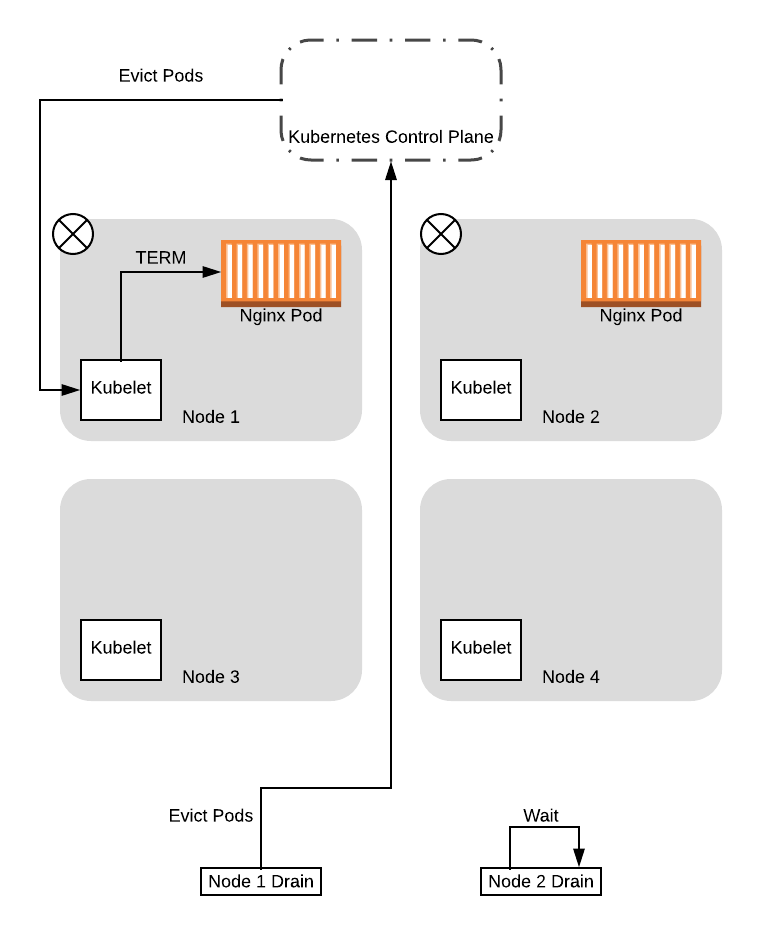
驱逐节点 1 中的 Pod 后,Deployment 控制器会立即在可用节点之一中重新创建 Pod。在这种情况下,由于我们的旧节点被 NoSchedule 污染,因此调度器将选择新节点之一:
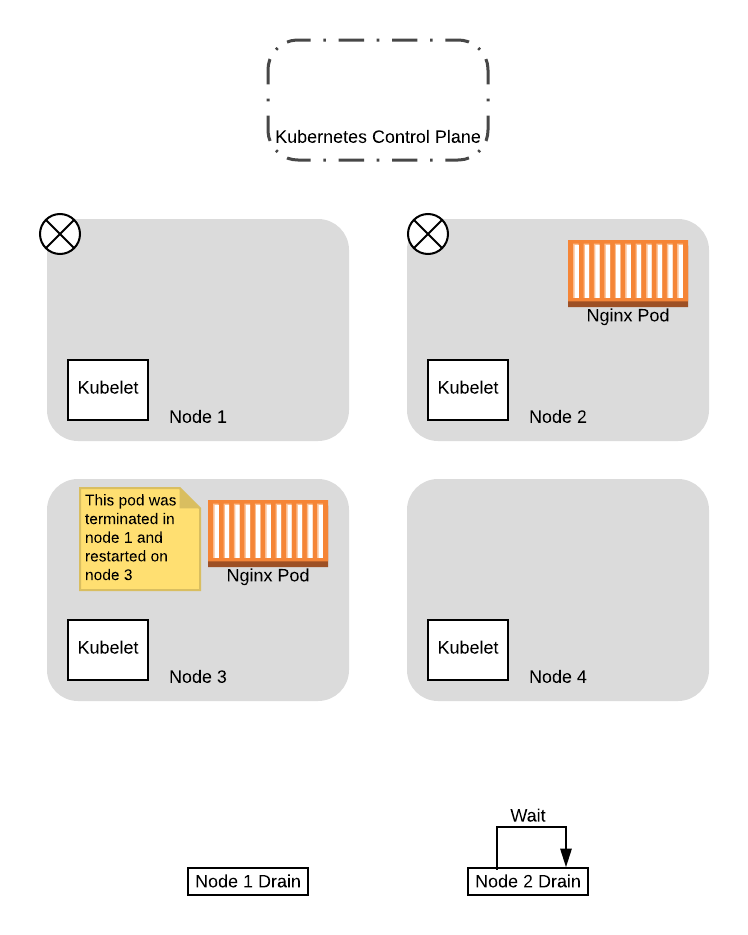
至此,既然已经成功在新节点上替换了 Pod,并且 drain 了初始节点,那么用于 drain 节点 1 的线程就完成了。
从这一点开始,当节点 2 的 drain 线程再次尝试向控制平面查询有关 PDB 时,它将成功。这是因为有一个正在运行的 Pod 不在考虑之列,因此,让节点 2 的 drain 线程继续运行不会将可用 Pod 的数量降低到预算以下。因此线程继续运行以驱逐 Pod,并最终完成驱逐过程:
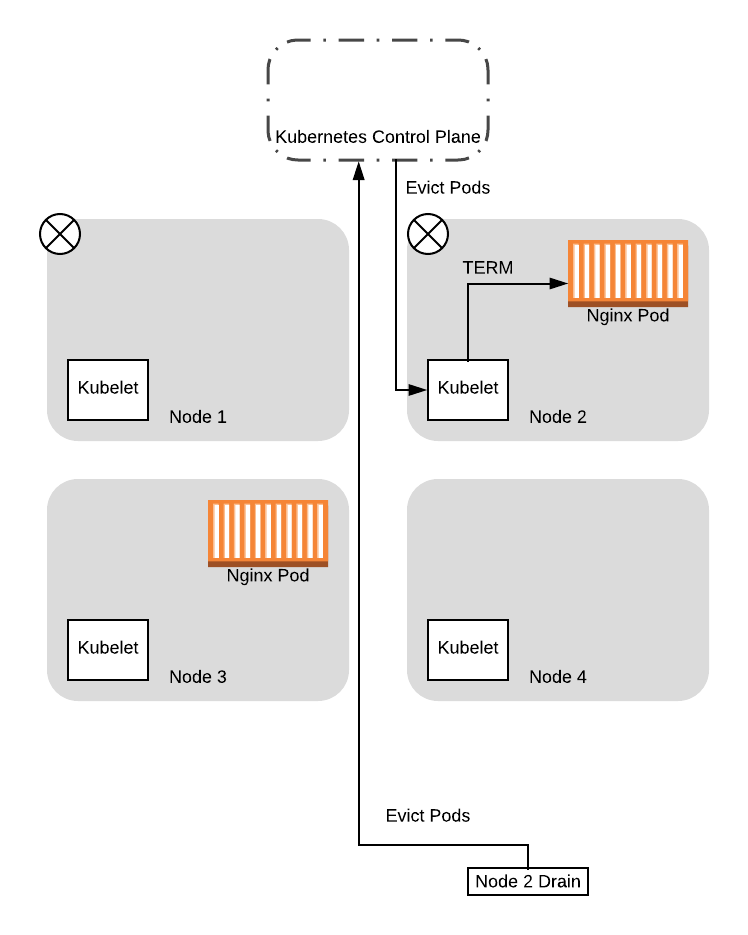
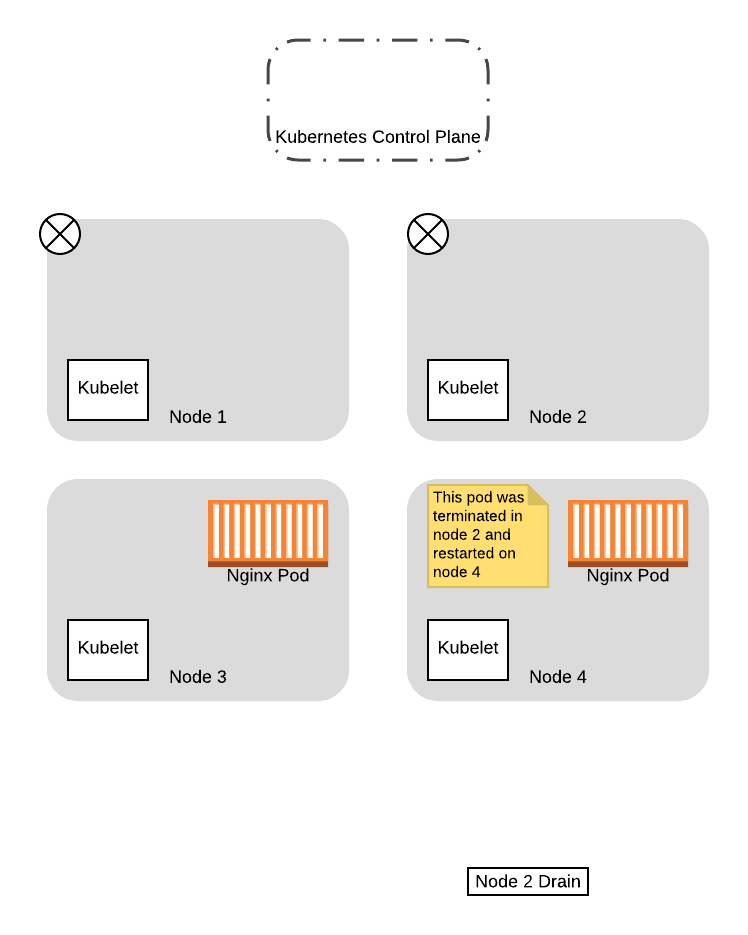
这样,我们就成功地将两个 Pod 都迁移到了新节点上,而且没有遇到没有 Pod 可用于为应用程序提供服务的情况。此外,我们不需要在两个线程之间有任何协调逻辑,因为 Kubernetes 会根据我们提供的配置为我们处理所有工作!
总结
最后将所有这些联系在一起,在本博客系列文章中,我们介绍了:
- 如何使用生命周期钩子来实现优雅关闭我们的应用程序的功能,以使它们不会突然中止。
- 如何从系统中移除 Pod,以及为什么必须在关闭序列中引入延迟。
- 如何指定 Pod 中断预算,以确保我们始终有一定数量的 Pod 可用,以便在中断情况下为功能正常的应用程序持续提供服务。
当所有这些功能一起使用时,我们可以实现零实例更新停机时间的目标!
但是不要只听我的话!继续进行此配置。您甚至可以利用 terratest 编写自动化测试,这可以利用 k8s 模块中的功能以及连续检查 endpoint 的能力。毕竟,我们从编写 30 万行基础结构代码中学到的重要经验之一就是,没有自动化测试的基础结构代码是不完整的。