【译文】延迟关闭以等待 Pod 删除传播

延迟关闭 Kubernetes 中的 Pod
这是实现 Kubernetes 集群零停机时间更新的旅程的第三部分。在本系列的第二部分中,我们通过利用生命周期钩子来实现应用程序 Pod 的正常终止,从而减轻了因不正常关机而导致的停机时间。但是我们还了解到,启动关闭序列后,Pod 可能会继续接收流量。这意味着最终客户端可能会收到错误消息,因为它们被路由到了不再能够为流量提供服务的 Pod。理想情况下,我们希望 Pod 在被逐出后立即停止接收流量。为了减轻这种情况,我们必须首先了解为什么会这样。
这篇文章中的许多信息都是从 MarkoLukša 的“Kubernetes in Action”一书中学到的。您可以在此处找到相关部分的节选。除了此处介绍的材料外,本书还提供了在 Kubernetes 上运行应用程序的最佳时间的出色描述,我们强烈建议您阅读。
Pod 关闭序列
在上一篇文章中,我们介绍了 Pod 驱逐生命周期。如果你从该文章中回想起,逐出序列的第一步是要删除 Pod,这会引发一系列事件,最终导致 Pod 从系统中删除。但是,我们并没有谈论的是,如何从 Service 中注销 Pod,以使其停止接收流量。
那么,是什么原因导致 Pod 从 Service 中被删除呢?为了理解这一点,我们需要更深入地了解从集群中删除 Pod 时会发生什么?
通过 API 将 Pod 从集群中删除后,所有发生的事情就是该 Pod 在元数据服务器中被标记为要删除。这会向所有相关子系统发送一个 Pod 删除通知,然后处理该通知:
- 运行 Pod 的
kubelet将启动上一篇文章中描述的关闭顺序。 - 所有节点上运行的
kube-proxy守护程序将从iptables中删除 pod 的 ip 地址。 - endpoint 控制器将从有效 endpoint 列表中删除该 Pod,然后从
Service中删除该 Pod。
您无需了解每个系统的详细信息。这里的重点涉及多个系统,这些系统可能在不同的节点上运行,并且这些序列并行发生。因此,将 Pod 从所有活动列表中删除之前,Pod 很有可能运行 preStop 钩子并接收到 TERM 信号。这就是为什么即使在启动关闭序列后,Pod 仍继续接收流量的原因。
缓解问题
从表面上看,我们似乎想要做的是将事件序列链接起来,以便直到从所有相关子系统注销了 Pod 之后,Pod 才会关闭。但是,由于 Kubernetes 系统的分布式性质,在实践中很难做到这一点。如果其中一个节点遇到网络分区会怎样?您是否无限期地等待传播?如果该节点重新联机怎么办?如果必须等待 1000 个节点怎么办?成千上万怎么办?
不幸的是,这里没有放置所有中断的完美解决方案。但是,我们可以做的是在关闭序列中引入足够的延迟以捕获 99% 的情况。为此,我们在 preStop 钩子中引入了一个 sleep,以延迟关闭序列。在我们的示例中,让我们看看它是如何工作的。
我们将需要更新配置以将延迟引入为 preStop 钩子的一部分。在“Kubernetes in Action”中,Lukša 建议使用 5-10 秒,因此在这里我们将使用 5 秒:
lifecycle:
preStop:
exec:
command: [
"sh", "-c",
# Introduce a delay to the shutdown sequence to wait for the
# pod eviction event to propagate. Then, gracefully shutdown
# nginx.
"sleep 5 && /usr/sbin/nginx -s quit",
]
现在让我们来看一下示例中关闭序列期间发生的情况。像上一篇文章一样,我们将从 kubectl drain 开始,它将逐出节点上的 Pod。这将发送一个删除 Pod 事件,该事件同时通知 kubelet 和 endpoint 控制器(管理 Service endpoint)。在此,我们假设 preStop 钩子在控制器删除 Pod 之前启动。
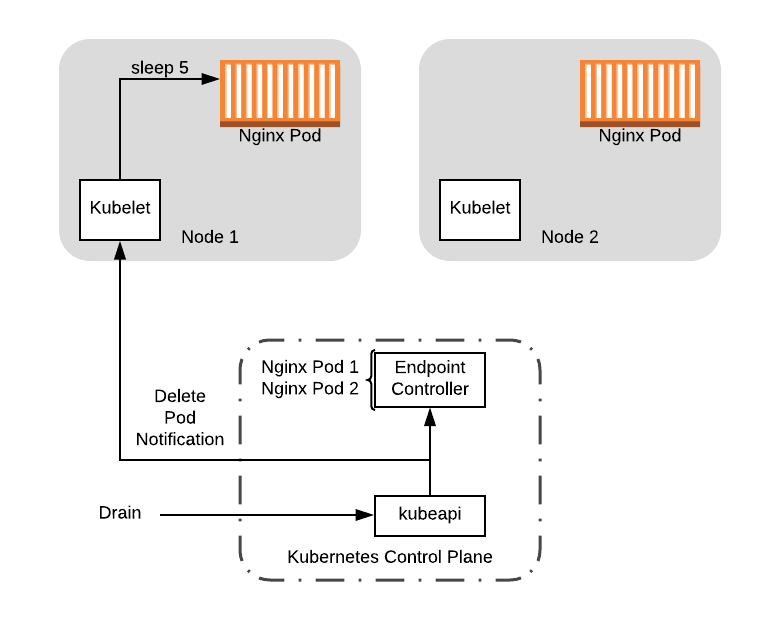
Drain 节点将删除 Pod,Pod 又发送一个删除事件。
此时,preStop 钩子启动,这将使关闭序列延迟 5 秒。在这段时间中,endpoint 控制器将移除 Pod:
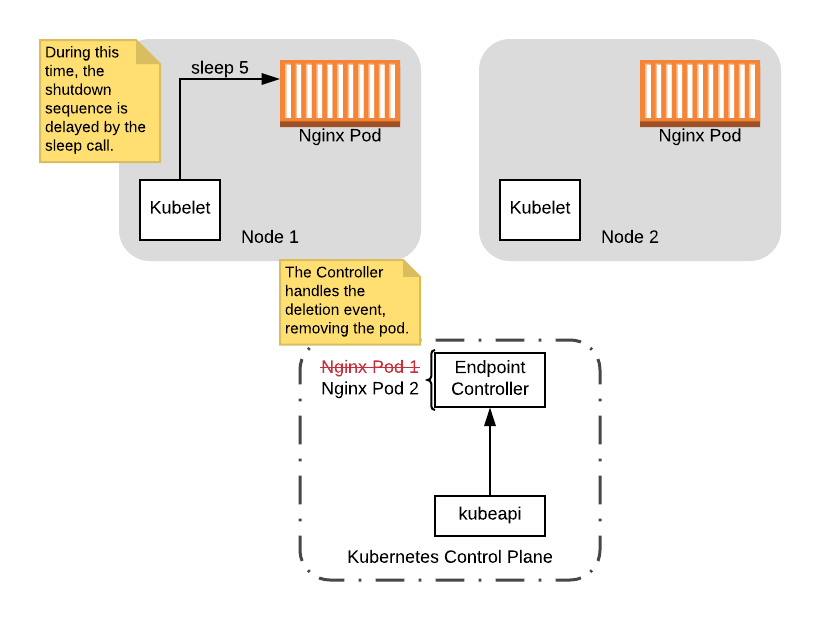
在延迟关闭序列的同时,将 Pod 从控制器上移除。
请注意,在此延迟期间,Pod 仍处于启动状态,因此即使其接收到连接,Pod 仍能够处理连接。此外,如果在将 Pod 从控制器移除后,任何客户端尝试连接,它们将不会路由到正在关闭的 Pod。因此在这种情况下,假设控制器在延迟时间内处理事件,则不会出现停机时间。
最后,为了完成关闭序列,preStop 钩子从休眠中退出并关闭 Nginx Pod,从该节点中移除 Pod:
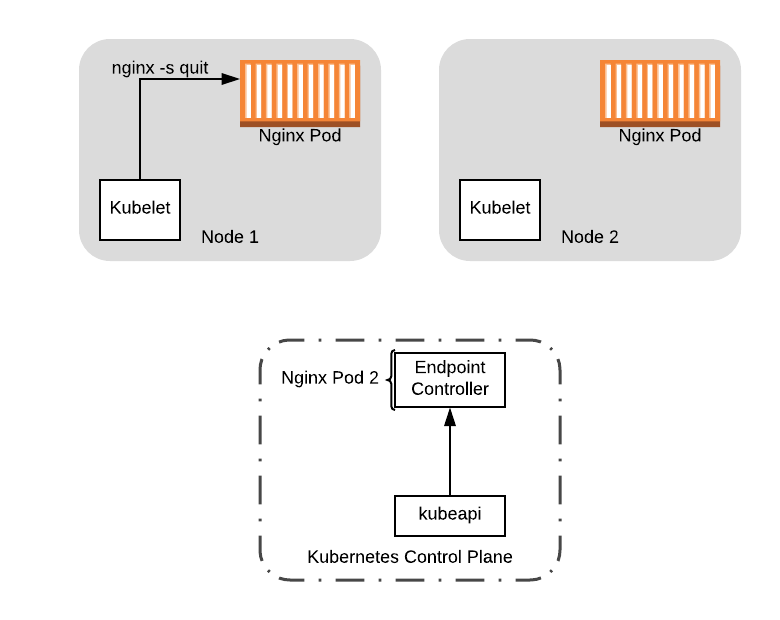
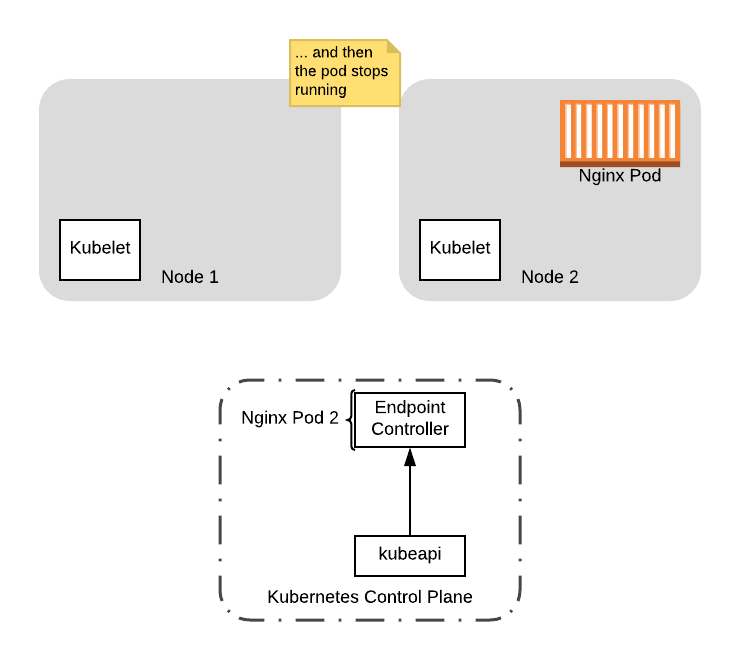
此时,可以安全地在节点 1 上进行任何升级,包括重新引导节点以加载新的内核版本。如果我们启动了一个新节点来容纳已经在其上运行的工作负载,那么我们也可以关闭该节点(请参阅下一节 PodDisruptionBugdgets)。
重建 Pod
如果到目前为止,您可能想知道我们如何重新创建最初在节点上调度的 Pod。现在我们知道了如何优雅关闭 Pod,但是如果要恢复运行的 Pod 的原始数量至关重要,该怎么办?这是 Deployment 资源发挥作用的地方。
Deployment 被称为控制器,它负责在集群上维护指定的所需状态。如果您还记得我们的资源配置,我们并没有直接在配置中创建 Pod。取而代之的是,我们通过使用 Deployment 资源为模板提供如何创建 Pod 的模板,从而自动为我们管理 Pod。这是我们配置中的 template 部分:
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15
ports:
- containerPort: 80
这指定了应使用标签 app:nginx 和一个运行 nginx:1.15 镜像的容器在 Deployment 中创建 Pod,并暴露 80 端口。除了 Pod 模板之外,我们还为 Deployment 资源提供了一个 spec,用于指定应维护的副本数:
spec:
replicas: 2
这会通知控制器它应尝试维护集群上运行的两个 Pod。只要运行的 Pod 数量下降,控制器将自动创建一个新的 Pod 来替代它。因此,在本例中,当我们在 drain 操作期间从节点中驱逐 Pod 时,Deployment 控制器会在其他可用节点之一上自动重新创建 Pod。
总结
总而言之,由于 preStop 钩子中有足够的延迟和优雅终止,我们现在可以在单个节点上正常关闭 Pod。利用 Deployment 资源,我们可以自动重新创建关闭的 Pod。但是,如果我们想一次替换集群中的所有节点怎么办?
如果直接 drain 所有节点,则可能会导致停机,因为 Service 负载均衡器可能最终没有可用的 Pod。更糟糕的是,对于有状态的系统,我们可能会耗尽选举数量,从而随着新 Pod 的出现而导致停机时间延长,并且必须经过 leader 选举,以等待一定数量的节点重新出现。
如果改为一次 drain 一个节点,那么最终可能会在其余的旧节点上启动新的 Pod。这种情况也存在风险,我们可能遇到所有的 Pod 被调度到同一个旧的节点,并且当我们 drain 该节点时,我们还是会失去所有的 Pod 副本。
为了处理这种情况,Kubernetes 提供了一个称为 PodDisruptionBudgets 的功能,该功能指定了在任何给定的时间点可以关闭的 Pod 数量的阈值。在本系列的下一个也是最后一部分,我们将介绍如何使用它来控制同时发生的 drain 事件的数量,尽管我们采用了原始的方式为所有节点发出了 drain 调用请求。